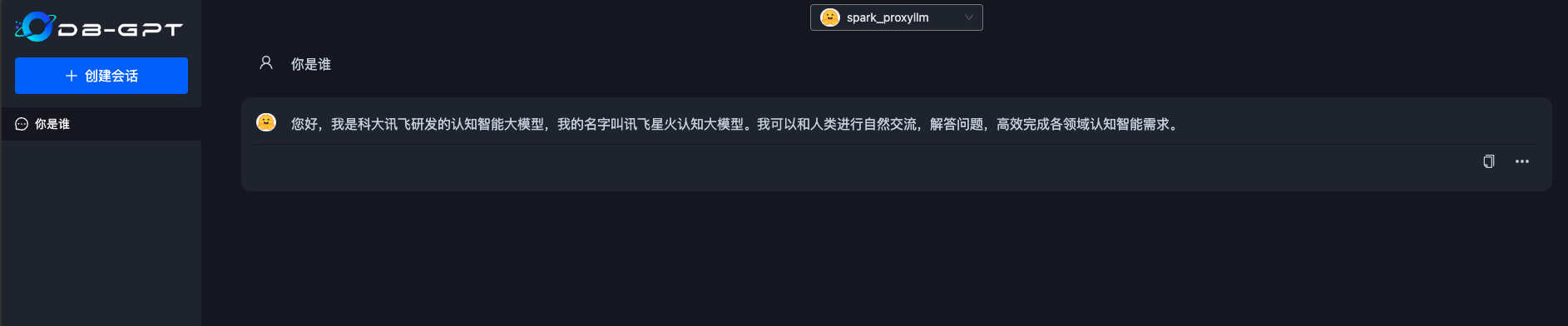
DB-GPT本地部署体验讯飞星火大模型V3.5
首先我们从 DB-GPT官网,可以得到的https://docs.dbgpt.site/docs/latest/quickstart
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL(Agentic Workflow Expression Language) and Agents)。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。
数据3.0 时代,基于模型、数据库,企业/开发者可以用更少的代码搭建自己的专属应用
本次 我们通过代理模型方式,使用讯飞星火大模型3.5版本,来进行验证部署。
需要提前将Miniconda环境安装
环境配置
首先根据官方文档说明,下载源码,并配置环境(python >= 3.10)
1 | // 拉取源码 |
创建环境
1 | // 创建环境 |
文本向量模型配置
在项目目录下,创建一个models文件夹,用来存放模型文件
1 | mkdir models and cd models |
下载模型,国内访问不了https://huggingface.co/GanymedeNil/text2vec-large-chinese
可以替换为镜像站https://hf-mirror.com/GanymedeNil/text2vec-large-chinese
1 | git clone https://hf-mirror.com/GanymedeNil/text2vec-large-chinese |
配置星火3.5模型
因为源码中没有3.5的API,需要手动修改一下代码,主要需要修改/DB-GPT/dbgpt/model/proxy/llms/spark.py
直接将3.1改为3.5即可使用

然后在.env文件中 将以下星火相关的配置替换即可
1 | LLM_MODEL=spark_proxyllm |
启动项目
1 | python dbgpt/app/dbgpt_server.py |
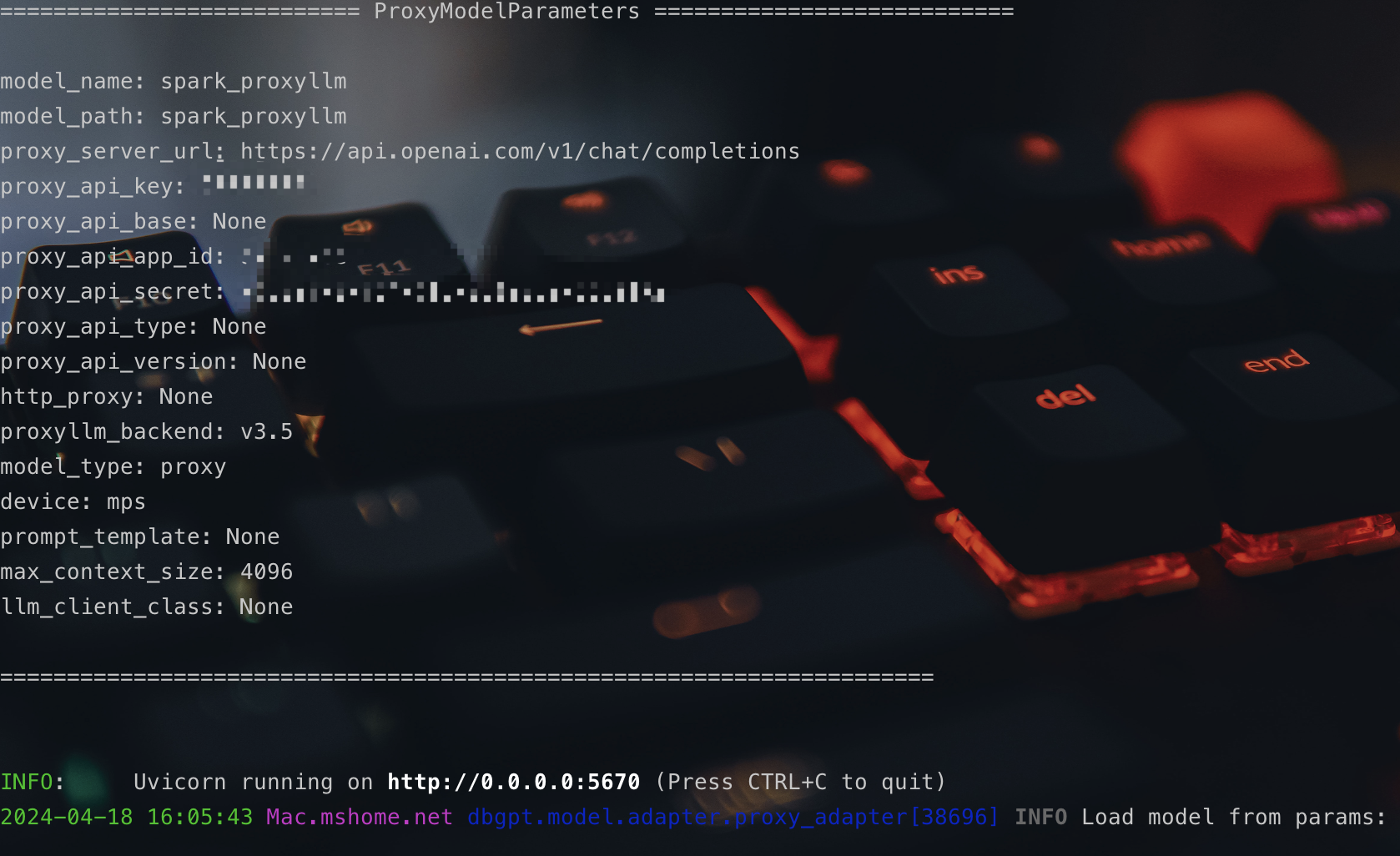
看到日志输出启动完成,打开浏览器访问http://localhost:5670