K8s搭建Flink集群并用StreamPark管理
前面文章中,成功搭建了K8s集群。这篇文章就开始来搭建组件了!
实时即未来 Apache Flink被普遍认为是下一代大数据流计算引擎。官网地址:https://flink.apache.org
Apache StreamPark之前也叫做 Streamx。是Flink开发利器。官网地址:https://streampark.apache.org
所以本文内容:K8s搭建Flink集群并用StreamX管理。
前提说明
官方文档地址如下:
- K8s Flink : https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/resource-providers/native_kubernetes
- StreamX : https://streampark.apache.org/zh-CN/docs/user-guide/deployment
依托于 StreamX一站式管理 和 K8s强大的调度管理。Flink集群的搭建算是比较简单了,按照官方文档一步一步就可以完成搭建。
K8s Flink 有要求 Kubernetes >= 1.9 前面装的1.22是满足的。
部署Flink集群
环境配置
首先登录k8smaster节点机器,检查kubectl是否正常
1 | # 查看集群信息 |
输出集群信息,证明kubectl连接正常即可
1 | Kubernetes control plane is running at https://192.168.31.190:6443 |
接下来Kubernetes RBAC配置
1 | # 创建命名空间 |
这样K8s这边准备工作就全部完成了,是不是很简单。那是因为把所有的创建和管理全部用StreamX去承载了。
如果不使用StreamX。那么也可以直接使用Flink官方文档上的配置进行Flink安装,但是那样是需要用命令方式提交任务和管理的,不太方便。
安装StreamX
StreamX就直接安装在K8smaster所在机器上了,但需要提前准备一些环境:
- JAVA 1.8+(需要安装在部署机器上)
- MySQL 5.6+(安装在部署机器或者其他机器已经有MySQL也行)
- Flink版本必须是1.12.x或以上版本, scala版本必须是2.11
解压缩之后,cd进入该目录,可以看到目录结构如下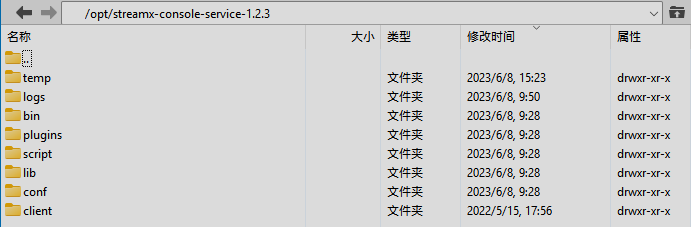
需要修改目录conf/application.yml文件中的三处
(Mysql连接信息、本地存储位置、docker仓库的命名空间)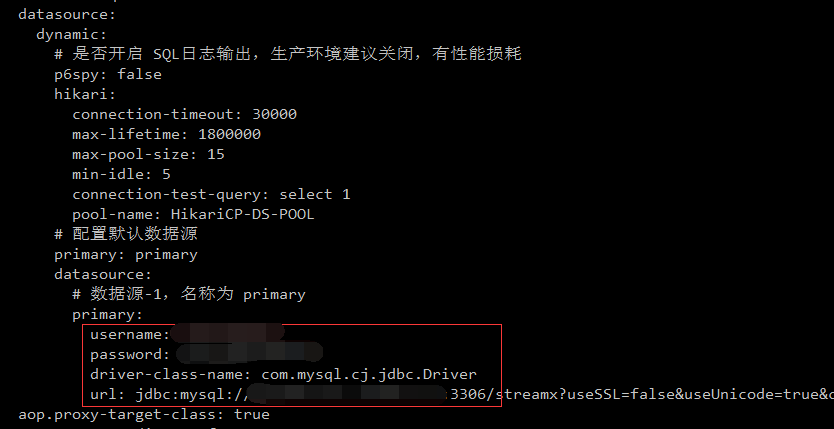
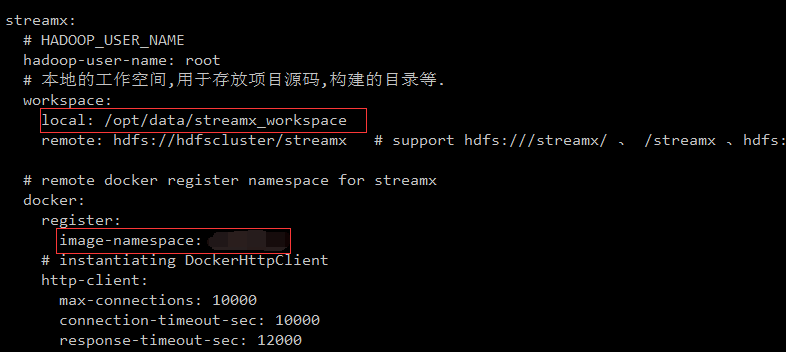
接下来,在Mysql创建一个数据库streamx。并找到目录script/final.sql 执行这个SQL脚本。完成表和数据导入。
启动streamx
1 | ./bin/startup.sh |
会输出一连串启动日志,最后一行[StreamX] StreamX start successful. pid: xxxx。就证明启动成功了
游览器打开:IP:10000端口,访问,输入默认账号密码admin / streamx
streamx配置
首先找到设置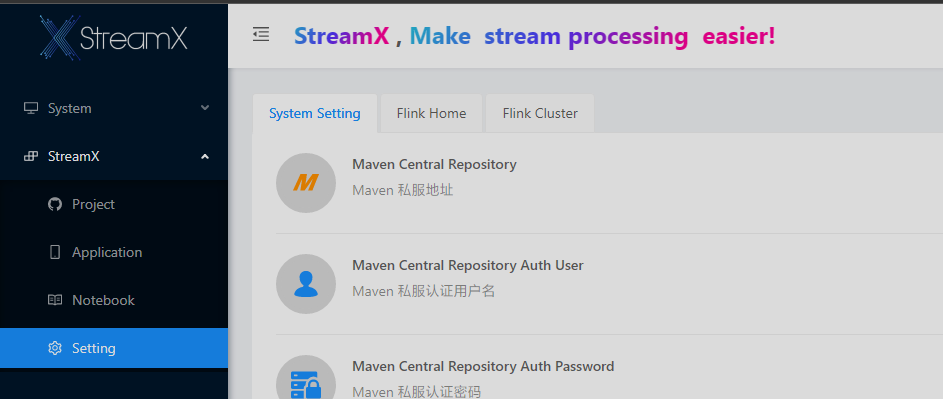
先配置系统设置,Flink搭建目前只需要配置 最下面的 Docker三项
- Docker Register Address
- Docker Register User
- Docker Register Password
再点击Flink Home配置,可以配置多个不同版本Flink
按照StreamX的环境要求,选择scala版本必须是2.11,大家可以自由选择版本,只需要改动地址中的版本号,即可进入对应版本文档
- 1.17文档:https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/resource-providers/native_kubernetes/
- 1.13文档:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/deployment/resource-providers/native_kubernetes/
所以我这里下载1.13.6。下载地址:https://archive.apache.org/dist/flink/flink-1.13.6/
解压缩之后放到/opt/flinkpackages目录下。以后其他版本也放到这里
填入名称 和 目录位置 再点击提交即可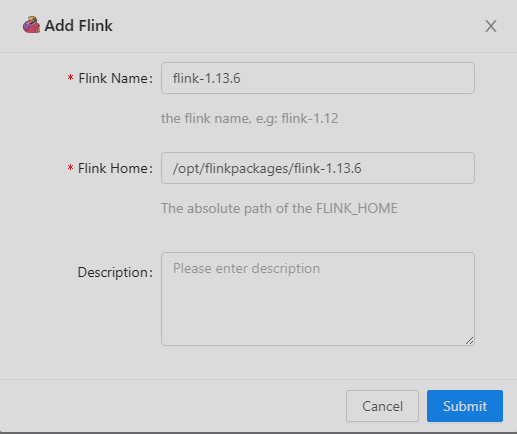
接下来开始配置集群信息,先创建一个Session集群,这里先简单配置一下,验证整个流程是否通顺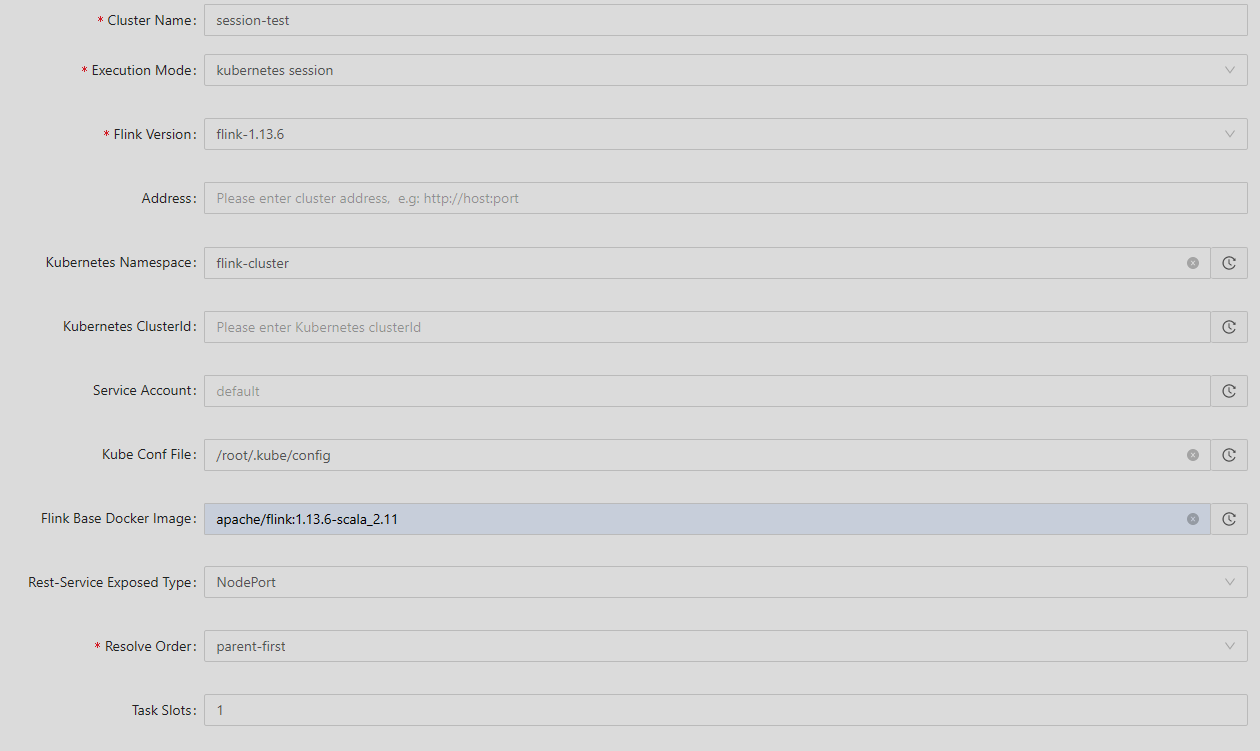

启动完成之后,点击 小眼睛 按钮 直接跳转到Flink UI。
测试验证
点击 Application 按钮,看到有一个自带的Demo,点击编辑按钮
测试session模式部署任务
选择刚刚启动的Session-test集群,其他下面配置不用改,直接点提交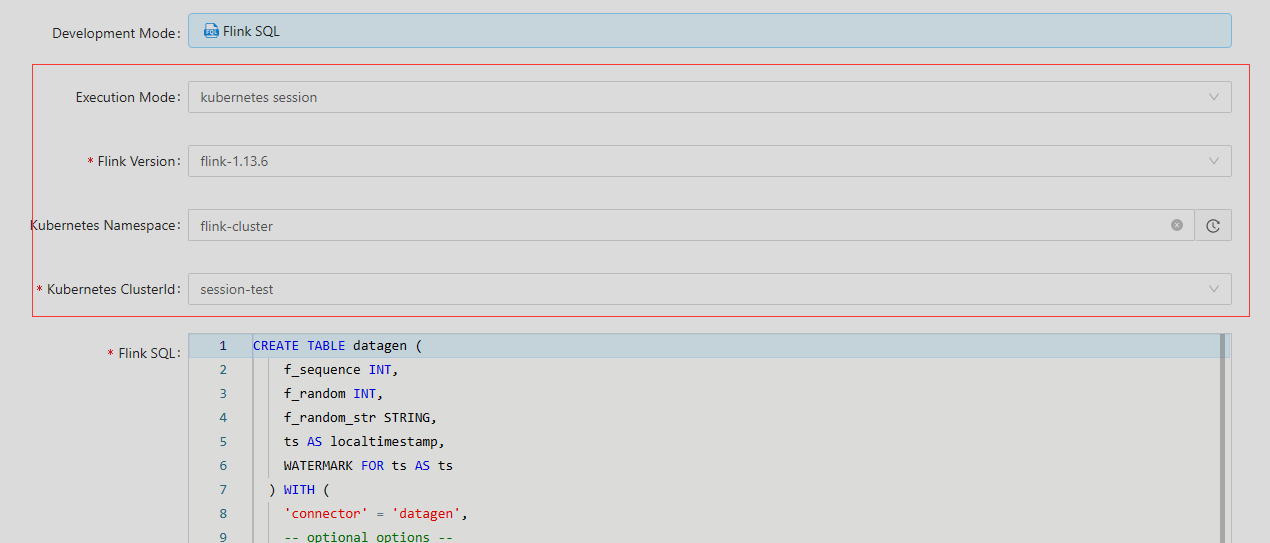
然后 点击第二个按钮Launch Application,等待编译完成之后 > 再次点击就是Start Application。会弹出启动配置窗口 > 关闭savepoint。再点击应用。
等待启动成功变为Running状态,点击小眼睛 按钮查看详细,可以跳转到Flink UI。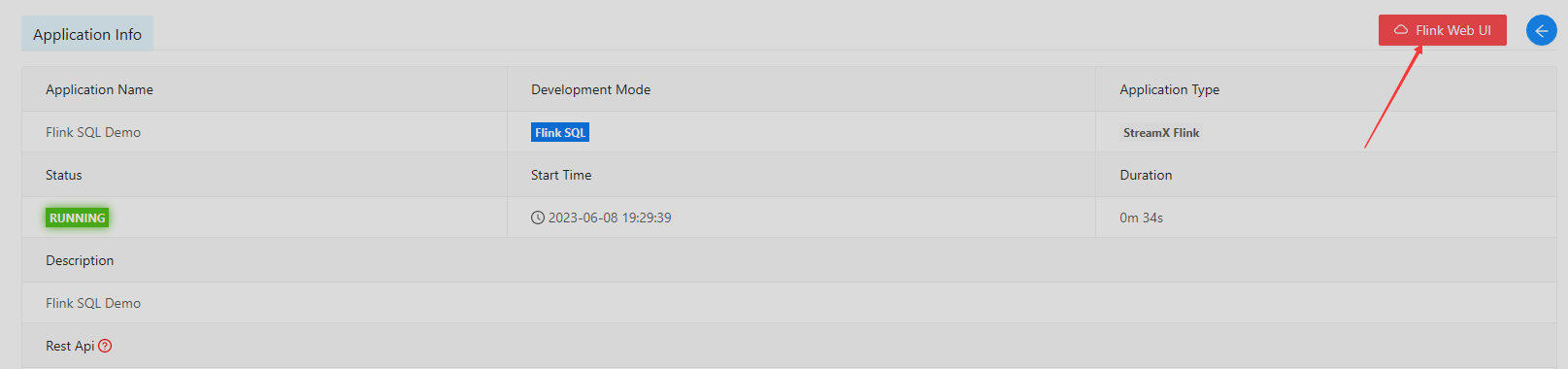
可以在Flink UIk看到在运行,这个Demo一会就跑完了。然后会自动伸缩TaskManagers
至此,整个Flink Session部署的流程就跑通了!
测试application模式部署任务
这里面有一个前提条件,需要预先在每台节点机器上登录docker私有仓库
1 | # docker login命令用于登陆到一个Docker镜像仓库,如果未指定镜像仓库地址,默认为官方仓库DockerHub(hub.docker.com)。 |
还是用上面的Flink SQL Demo,再次编辑,模式选择kubernetes application 自定义clusterId:test123,然后点提交。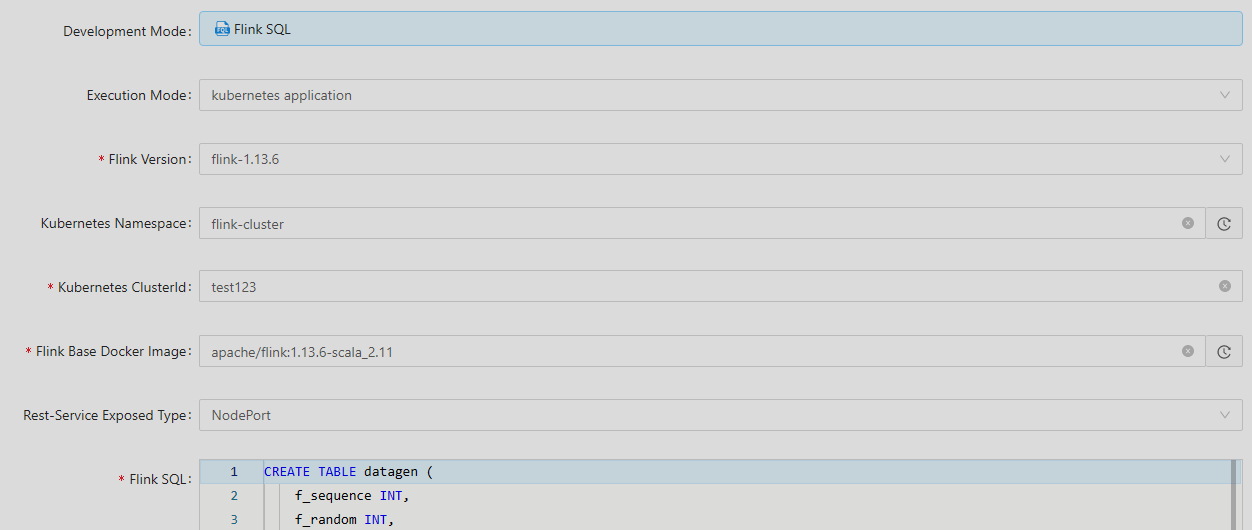
接下来就是和session集群一样的操作,点击第二个按钮Launch。等待docker镜像bulid完成并上传到docke仓库。就可以再次点击启动了
等待启动成功变为Running状态,点击小眼睛 按钮查看详细,可以跳转到Flink UI 进行查看。
至此,整个Flink application部署的流程也跑通了!
也可以直接在K8s Dashboard 查看,等待jobmanager和taskmanager都为running。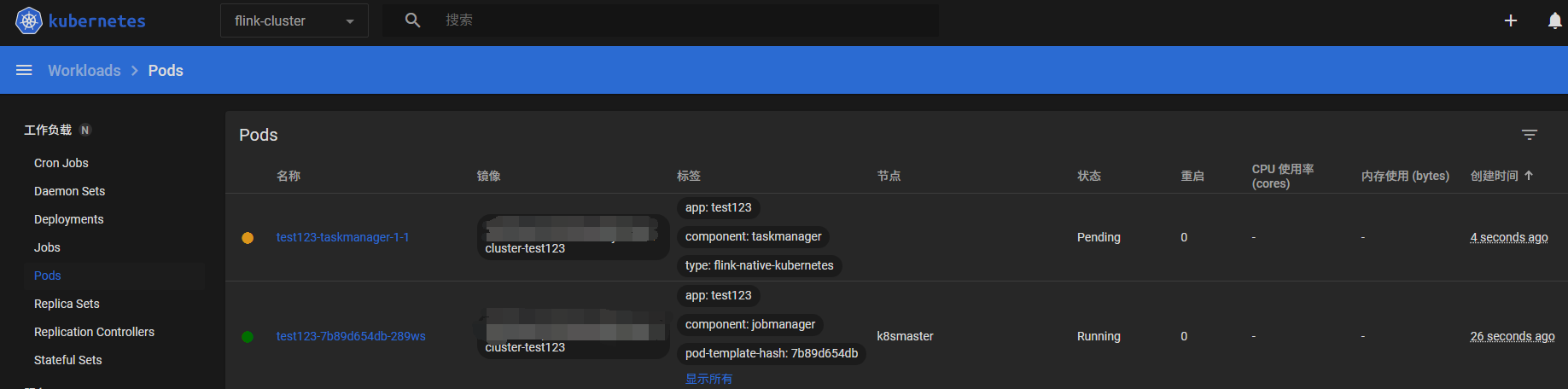
Flink 任务资源配置
接下来就是根据任务来合理配置不同的部署模式。合理利用资源。
高效利用资源,让K8s合理分配,可以从Flink官方文档中了解Flink的整个配置说明。
地址:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/deployment/config/#kubernetes
从文档中,我们可以看到所有配置项,可以直接在Streamx上直接对Flink集群进行配置 写在:“Dynamic Option” (一行一个配置,首位添加-D) 中 比如: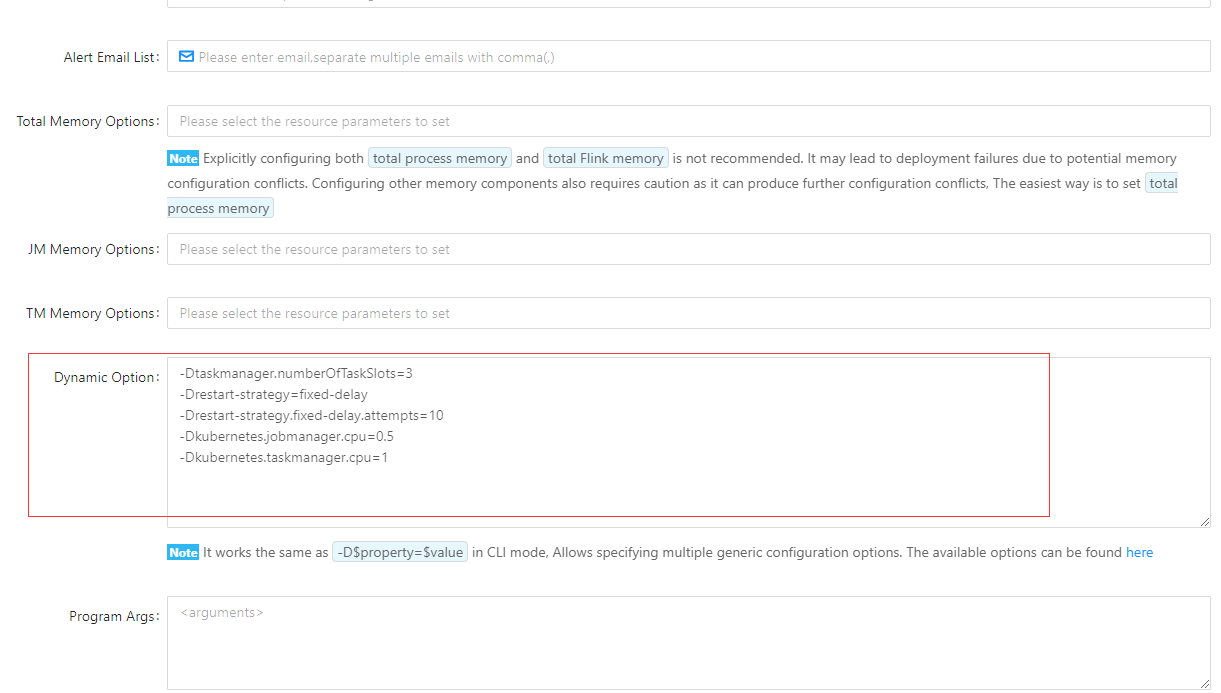
- 配置了一个TaskManger中有三个slot
- 配置了任务重启策略为固定间隔重启
- 配置了任务重启次数为10次
- 配置了K8s限制jobmangerCPU资源为0.5
- 配置了K8s限制taskmangerCPU资源为1
这样在Flink集群启动时,就会按照配置加载,从Flink UI中也可以看到集群的详细配置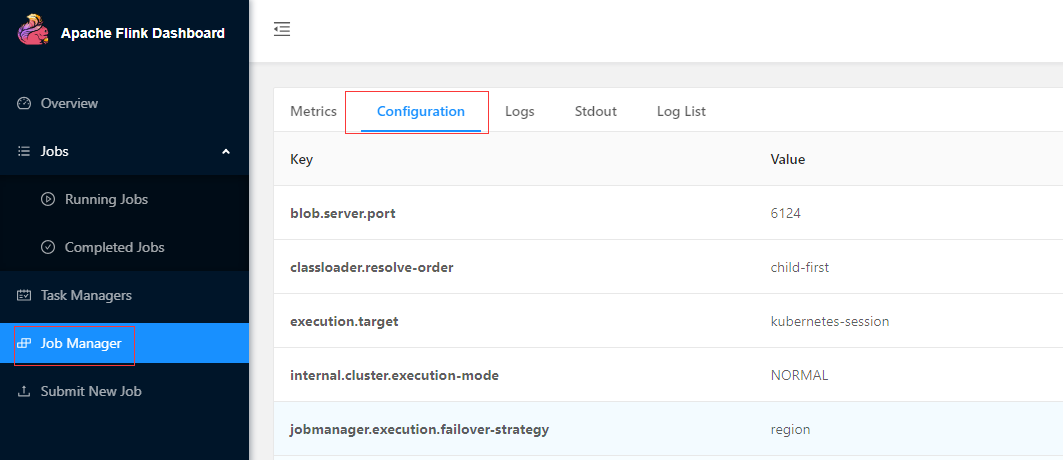
Flink镜像时区修改
用Flink的官方镜像,时区不是东八区,从日志打印也可以看出来慢了8个小时。所以我们需要构建自定义镜像,修改时区为东八区
首先创建一个Dockerfile
1 | FROM apache/flink:1.13.6-scala_2.11 |
在Dockerfil同级目录,执行build命令(注意命令最后有一点),打成自定义镜像。
1 | docker build -t streamx/flink:1.13.6-scala_2.11 . |
再推送到私服
1 | docker push streamx/flink:1.13.6-scala_2.11 |
接着修改集群设置中的镜像配置”Flink Base Docker Image”为新的自定义镜像,再次启动即可。
Streamx中使用UDF函数
在Flink SQL 中,会需要使用到自定义的UDF函数,来做一些复杂的计算。
首先我们创建一个Maven工程,Pom.xml引入基础的包,和业务需要的包即可
1 | <dependencies> |
然后创建自定义函数类,并继承Flink的ScalarFunction类,这里举例就简单实现拼接函数
1 | public class TestCalc extends ScalarFunction { |
将Maven工程打成Jar包,在Streamx中创建Flink SQL任务,并在Dependency一栏 选择 Upload Jar。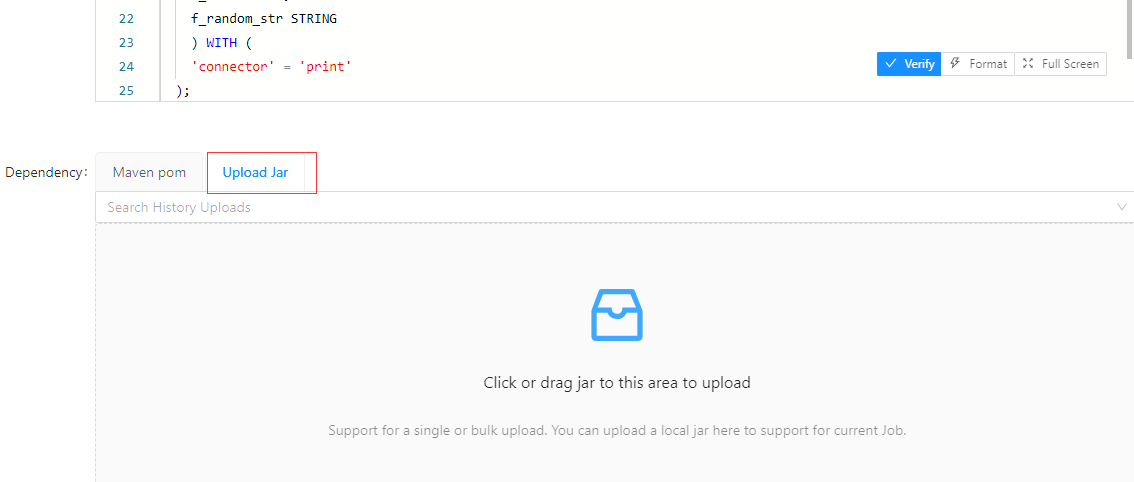
同时需要在SQL中添加 注册函数
1 | CREATE TABLE datagen ( |
